Movie Analysis
The Cognitive Science Movie Index (CSMI) has a few unique features that distinguish it from other movie lists. The first is our three-metric rating system: quality of the overall movie, accuracy in how the film portrays its central cognitive science theme, and relevance to the field of cognitive science. Beyond that, we applied a couple of other analyses to each movie to try and extract additional features related to cognitive science and relate the movies to encyclopedia articles within the field. We represented each movie as a vector space model using reviews from the Internet Movie Database (IMDb), and compared these vector representations to other CSMI movies, articles from the Stanford Encyclopedia of Philosophy (SEP), and articles from the MIT Encyclopedia of Cognitive Science (MITECS).
Building the bag-of-words model
A bag-of-words model is a type of vector space model used for representing a document by only the words it contains and their frequencies. Word order and grammar is disregarded. We used IMBb reviews to build this textual representation of the CSMI movies. Alternative options might have been movie scripts or plot descriptions, but we chose reviews for their abundance, availability, and tendency to discuss the content of the movie. Up to 1,000 reviews were gathered for each movie, and then combined to create one large text document per movie.
While we could have built a bag-of-words model from these documents without further processing, we wanted to not only relate movies to each other, but to encyclopedia articles as well. We needed to represent each document with words that were shared between all three of the corpora we are comparing (IMDb, SEP, and MITECS). We picked the MIT Encyclopedia of Cognitive Science as the base corpus, filtered words from it that were too frequent or too rare, removed first name-last name pairs, and added in commonly co-occurring words as bigrams. We ended up with a final vocabulary of 10,690 terms.
The original review-based documents for each movie were filtered with this vocabulary, and as a result the final documents only contained words that were also present in MITECS.
Generating top words with tf-idf
On a movie’s page, we display twenty of the most distinctive words from the original reviews for that movie and their weights. We transformed each movie’s initial bag-of-words model into a term frequency–inverse document frequency (tf-idf) model, which is designed to weight terms by their relative importance. Frequent words in a document are weighted lower if they are common across many documents, and rare words overall are weighted higher if they have a high frequency within the individual document.
The tf-idf weight for term i in document j was calculated as such:
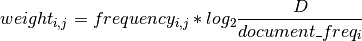
where frequencyi,j is the raw count from the bag-of-words model, D is the total number of documents in the corpus (the total number of movies), and document_freqi is the number of documents that term i appears in.
You’ll find that the top 20 terms we derive from this method are generally very descriptive of the movie, even though they were originally from reviews of everyday users on IMDb. Common review terms like "actor", "film", or "loved" are given a very low tf-idf weight, and the more distinctive terms bubble up instead.
Related Articles and Movies
In order to provide more scientific substance to a movie index about cognitive science, we related each movie to encyclopedia articles about topics in cognitive science. A subset of 469 articles from the MIT Encyclopedia of Cognitive Science and 209 articles from the Stanford Encyclopedia of Philosophy were picked out as relevant to cognitive science. We filtered these articles by the same vocab list extracted earlier, and applied the tf-idf model to them. This transformed every document into a 10690-dimensional vector of term weights, regardless of if it was a collection of movie reviews or an encyclopedia article.
We used cosine distance to measure the difference between any two documents. Cosine distance is one minus the cosine of the angle between two vectors; if the vectors are equal (and the angle between them is 0), then cosine distance is 0. If they are orthogonal to each other, the cosine distance is 1.
CD(X || Y) = 1 - cos(θ) = 1 - ( X · Y / ||X|| ·||Y||).
The “Related Articles” section of a movie’s page links to the ten most similar articles by distance, and the “Related Movies” section lists the nine most similar movies. Note that the MIT Encyclopedia of Cognitive Science is not open-access and requires an individual or university library subscription to view.
Our related article list is not perfect, since there are inherent drawbacks with both tf-idf and cosine distance for relating documents. The quality of the list also heavily depends on the terms users put in their reviews, and it’s rare for reviewers to closely discuss the deep scientific aspects of a film. Still, these articles often provide a good starting point for movie-watchers desiring to learn more about the cognitive science concepts of a film.
Further reading
The analysis described above is a subset of a senior thesis project done by Mac Vogelsang in collaboration with Brad Rogers and Peter Todd. For more information on the data presented on this site and the methods used, as well as the results of additional modelling, you can find the full paper here.